




L’intelligence artificielle (IA) est une branche de la science qui se consacre à la création de machines capables d’accomplir des tâches qui nécessiteraient normalement une forme d’intelligence humaine. Marvin Minsky, pionnier dans ce domaine, définit l’IA comme « la science qui consiste à faire faire aux machines des choses qui nécessiteraient de l’intelligence si elles étaient réalisées par des hommes ».
Fondée sur des mathématiques et des algorithmes, l’IA simule des fonctions cognitives humaines telles que l’apprentissage et la décision. Ce domaine scientifique se scinde en deux principales sous-disciplines : le Machine Learning et le Deep Learning.
I) le deep learning et machine learning : des sous-catégories de l’ia
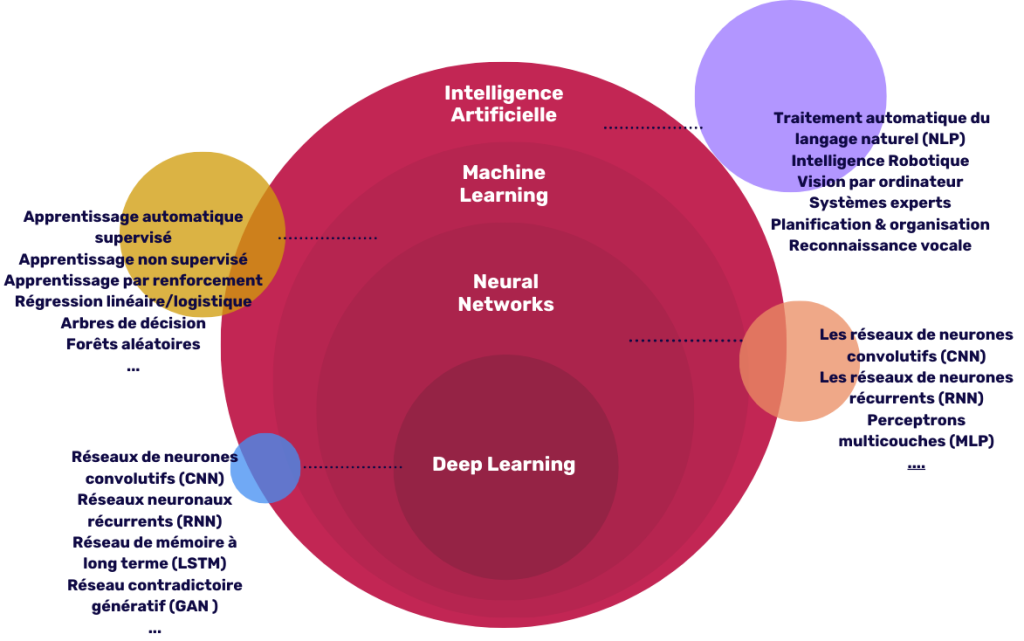
Bien que le deep learning et le machine learning soient souvent confondus, il est important de comprendre les distinctions entre les deux. En effet, le deep learning est en réalité une sous-catégorie du machine learning, lequel fait lui-même partie intégrante de l’intelligence artificielle.
Découvrez notre fiche & insight sur l’IA générative.
II) le machine learning : apprendre à partir des données

a) Les fondements du Machine Learning
L’apprentissage automatique classique, également appelé machine learning, est une technologie permettant aux machines d’apprendre de manière autonome à partir de données et d’améliorer leurs performances sans être explicitement programmées pour chaque tâche. Cette branche de l’IA s’appuie sur des algorithmes qui analysent des ensembles de données pour en extraire des modèles et faire des prédictions ou prendre des décisions basées sur de nouvelles données. Le potentiel de cette technologie réside dans sa capacité à traiter et analyser des volumes de données bien supérieurs à ceux qu’un humain pourrait gérer, ouvrant ainsi la voie à des applications telles que la reconnaissance vocale ou la détection de fraude.
b) Interaction humaine et apprentissage supervisé
Dans l’apprentissage automatique traditionnel, l’intervention humaine est essentielle. Considérons la classification d’images de restauration rapide, par exemple. Les experts commencent par identifier des caractéristiques clés, comme le type de pain sur les images de hamburgers, pizzas, et tacos. Ces caractéristiques sont ensuite utilisées pour étiqueter les images dans une base de données, simplifiant le processus d’apprentissage supervisé. En conséquence, le modèle apprend à différencier ces types de repas rapidement grâce aux indications fournies, mettant en évidence l’impact crucial de l’intervention humaine pour affiner les données d’entrée et améliorer la précision des résultats.
Téléchargez notre livre blanc sur l’IA générative
III) le deep learning : s’inspirer du cerveau humain

a) Introduction au Deep learning
Le Deep Learning s’inspire directement du fonctionnement du cerveau humain, utilisant des réseaux de neurones artificiels pour traiter et interpréter des quantités massives d’informations. Des modèles récents comme Deepseek R1 illustrent la puissance croissante des approches open source dans ce domaine. Le deep learning permet aux systèmes d’apprendre avec une précision élevée et de traiter les données à travers de multiples couches, ce qui améliore significativement leur capacité à reconnaître des patterns complexes. Cette approche est particulièrement efficace pour des applications comme la traduction automatique ou la reconnaissance d’images, où elle peut précisément identifier et classer les éléments d’importants ensembles de données.
b) Complexité et automatisation dans le Deep Learning
Le deep learning, une évolution du machine learning, traite des données non structurées comme le texte ou les images. Il identifie automatiquement des caractéristiques sans besoin d’étiquetage humain. Ce processus utilise des réseaux de neurones multicouches et fonctionne en modes supervisé ou non supervisé. La principale distinction avec le machine learning classique réside dans l’automatisation accrue et le nombre de couches neuronales. Le terme « profond » désigne des réseaux de plus de trois couches, illustrant leur complexité accrue.
Qu’entend-on par Neural Networks ou réseaux de neurones ?
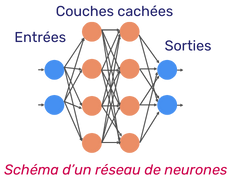
Un réseau de neurones artificiels consiste en des couches de nœuds avec une entrée, des couches cachées, et une sortie. Chaque nœud est connecté à d’autres avec des poids et des biais1. Les données traversent le réseau pour la reconnaissance de modèles. Il existe différents types de réseaux de neurones :
- le perceptron ;
- les réseaux de neurones Feedforward (MLP) ;
- les réseaux de neurones convolutifs (CNN) ;
- les réseaux de neurones récurrents (RNN).
En conclusion
Ainsi, l’intelligence artificielle, avec ses sous-disciplines le Machine Learning et le Deep Learning, continue de redéfinir les limites des technologies numériques et de transformer de manière significative une multitude de secteurs. Ces technologies traitent de grandes données, imitent ou surpassent l’humain, et transforment la santé, la finance ou l’industrie.
Le Machine Learning, avec apprentissage supervisé, et le Deep Learning, par automatisation complexe, révèlent la complexité de l’IA. Ces technologies ne cessent d’évoluer et promettent de continuer à offrir des innovations révolutionnaires qui façonneront notre futur. Toute entreprise souhaitant rester compétitive dans un paysage technologique en rapide évolution doit comprendre et adopter ces avancées. Découvrez dans un autre billet comment intégrer l’IA dans la stratégie globale de l’entreprise.
Vous souhaitez en savoir plus sur le sujet ou nous faire part de vos projets digitaux ambitieux ? Contactez nos experts dès à présent.
- ¹Les poids et les biais sont ajustés continuellement pour améliorer la précision du réseau de neurones, les poids étant appliqués aux entrées pour calculer les sorties, et les biais ajoutés après cette étape, formant ainsi des valeurs d’auto-apprentissage du réseau. ↩︎
