




Data hub vs data lake : ces deux concepts vous parlent-t-ils ?
Quoiqu’il en soit, vous avez sans doute déjà entendu parler de ces deux termes. En effet, un data hub et un data lake sont liés à l’architecture de données, mais ils ont des différences importantes. Nous vous présenterons quelques distinctions qui existent entre eux, ensuite nous vous évoquerons quelques considérations qui vous aideront à choisir la data architecture qui pourrait s’adapter à votre organisation.
Cependant, nous allons dans un premier temps comprendre les deux concepts afin de mieux saisir leurs divergences par la suite.
I. Comprendre le data hub et le data lake
1. Qu’est-ce qu’un data hub?
Le data hub ou point central de données est une plateforme centralisée qui agit comme un point de convergence pour diverses sources de données. Sa principale mission est de faciliter l’intégration des données, de les rendre accessibles et de garantir leur qualité.
Les caractéristiques clés d’un data hub incluent une architecture modulaire, une gestion efficace des métadonnées et une intégration transparente avec d’autres systèmes.
1.1. Quels sont les défis liés au data hub?
- Intégration des données: L’un des défis du data hub est l’intégration efficace de données provenant de sources diverses. Les différentes structures et formats peuvent rendre cette tâche complexe, nécessitant une planification minutieuse pour garantir une intégration fluide.
- Gestion de la qualité des données: Avec la variété des sources de données, maintenir la qualité des données peut être un défi. Des incohérences, des erreurs ou des duplications peuvent surgir, impactant la fiabilité des informations extraites du data hub.
- Sécurité et confidentialité: La centralisation des données dans un data hub soulève des préoccupations en matière de sécurité et de confidentialité. Protéger les données sensibles contre les accès non autorisés et les violations de sécurité est une priorité, nécessitant des mesures robustes de gestion des accès et de chiffrement.
- Coût et stratégie de mise en place: La création d’un data hub peut nécessiter des investissements significatifs en termes de matériel, de logiciels et de ressources humaines. Aussi, la mise en place d’une stratégie d’un data hub peut se heurter à des difficultés. Selon Gartner :
« La stratégie d’un data hub est passée du statut du déclencheur d’innovation au creux de la désillusion en juin 2022. »
Gartner, Hype cycle for Data Management, 2022
Téléchargez le livre blanc sur la data observability
2. C’est quoi un data lake?
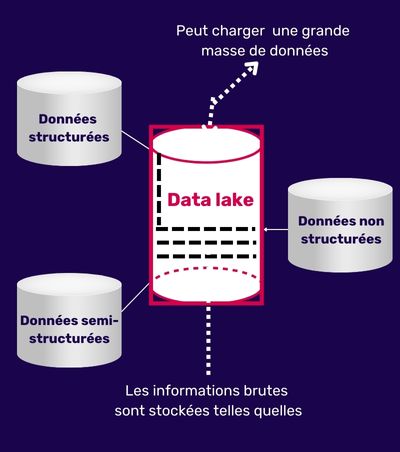
Un data lake ou lac de données est un référentiel de données massif et flexible qui stocke des informations brutes sous leur forme originale. Il offre une capacité de stockage évolutive et est idéal pour stocker des données non structurées.
Les avantages du data lake résident dans sa capacité à gérer d’énormes volumes de données sans la nécessité d’une structuration préalable.
Rappel : Comme nous l’avons indiqué dans notre article sur les tendances de l’architecture de données en 2024, les data lakes ont émergé en 2024. Selon Victor Coustenoble, expert en architecture de solutions chez Starburst pour l’Europe du Sud : « On observe une tendance émergente vers des data lakes on-premises basés sur un stockage d’objets sans couches Hadoop, qui offrent une alternative moins complexe. »
2.1. Quels sont les défis d’un data lake?
- Gestion du volume de données: Les lacs de données sont conçus pour stocker de grandes quantités de données, mais cette capacité peut devenir un défi en soi. En effet, la gestion des données non structurées peut être complexe, et la recherche de l’information pertinente peut être comme chercher une aiguille dans une botte de foin.
- Qualité des données: Avec la diversité des sources de données alimentant le data lake, la qualité des données peut être difficile à maintenir. Les incohérences, les erreurs et les duplications peuvent compromettre la fiabilité des informations extraites du data lake.
- Sécurité et confidentialité: La sécurité des données dans un data lake est un point sensible. La centralisation de données brutes nécessite des mesures de sécurité robustes pour protéger contre les accès non autorisés, les violations de confidentialité et les attaques potentielles.
II. Quelles sont les différences entre un data hub et un data lake ?
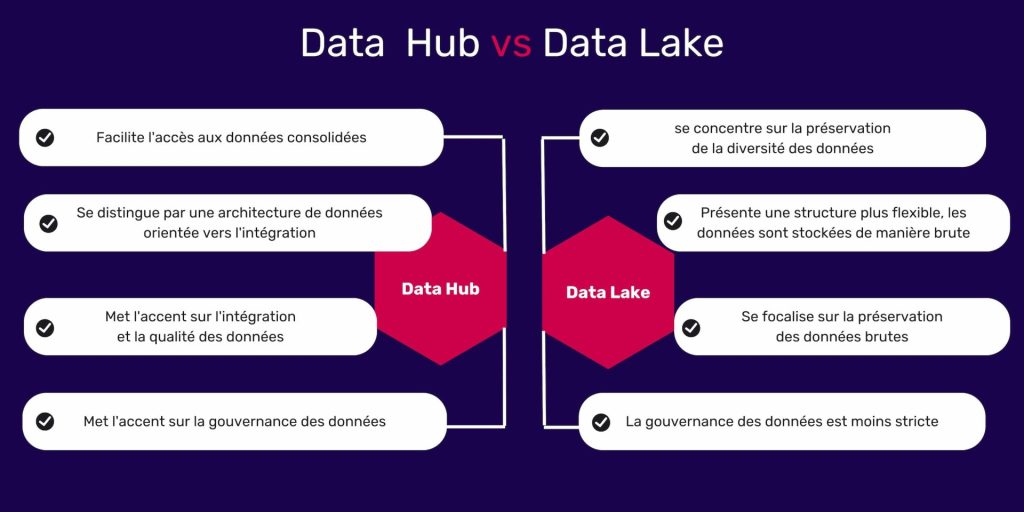
Les différences entre un data hub vs un data lake se font remarquer sur plusieurs points, notamment : leurs objectifs et fonctions, leurs architectures, le stockage et traitement de données ainsi que la gouvernance des données.
1. Objectifs et fonctions
Le data hub ou nœud de données vise à fournir un accès rapide et facile aux données consolidées, favorisant une prise de décision informée. Il agit comme un hub central pour l’intégration et la distribution des données.
Par ailleurs, le data lake se concentre sur la préservation de la diversité des données, sans imposer de structure préalable. Son objectif principal est de stocker toutes les données, qu’elles soient utilisées immédiatement ou non.
2. Architecture et structure
Le data hub a une data architecture plus ciblée, mettant l’accent sur l’intégration des données. Il organise les données de manière structurée, facilitant l’accès et la recherche.
En revanche, le lac de données offre une structure plus flexible. Les données y sont stockées de manière brute, permettant une analyse approfondie ultérieure sans contraintes initiales.
3. Stockage et traitement de données
Aussi, la différence entre un data hub vs un data lake réside dans leur approche de stockage, de traitement et d’accessibilité des données.
Par conséquent, le data hub privilégie l’intégration et la qualité des données, le data lake se concentre sur la conservation des données brutes tout en permettant des analyses plus approfondies.
4. Gouvernance des données
Le data hub met l’accent sur la gouvernance des données pour assurer la qualité et la cohérence des informations partagées.
Cependant, la gouvernance est moins rigide dans un data lake en raison de la variété des données stockées.
Récapitulatif des différences entre un data hub et un data lake
III. Quelle est la bonne architecture de données à choisir ?
Maintenant que vous pouvez distinguer ces deux architectures de données, il ne reste plus qu’à choisir la data architecture qui puisse vous convenir.
Le choix à faire entre un data hub vs un data lake dépend des besoins spécifiques de votre organisation en matière de gestion des données.
Néanmoins, nous vous proposons quelques considérations pour vous aider à prendre une décision :
1. Nature des données :
- Data hub : convient mieux si vous avez principalement des données structurées et si vous avez besoin d’une gestion centralisée des métadonnées.
- Data lake : Idéal pour stocker une grande variété de données, qu’elles soient structurées, semi-structurées ou non structurées.
2. Flexibilité et agilité :
- Data hub : Peut être plus adapté si vous avez besoin d’une solution plus agile et rapide à mettre en œuvre, avec une approche centrée sur les données métier.
- Data lake : Offre une flexibilité accrue pour ingérer et stocker divers types de données, ce qui peut être avantageux dans un contexte où les besoins évoluent rapidement.
3. Analytique et traitement des données :
- Data hub : Bien adapté pour des scénarios d’analyse spécifiques, avec des données généralement préparées et organisées.
- Data lake : Fournit une plateforme plus puissante pour l’analyse de données massives. De même, l’exploration de données et la mise en œuvre de scénarios d’analyse avancée.
4. Sécurité et conformité :
- Data hub : Peut être plus facile à sécuriser en raison de la nature plus contrôlée des données.
- Data lake : Nécessite une attention particulière en matière de sécurité, en raison de la variété des données et des niveaux d’accès.
Data hub vs data lake : ce qu’il faudrait retenir
Bien que le choix entre un data hub et un data lake dépende des besoins spécifiques de chaque organisation, il est important de reconnaître que ces deux approches offrent des avantages distincts :
- Le data hub se distingue par sa focalisation sur l’intégration et la facilité d’accès aux données,
- le lac de données excelle dans le stockage massif et la diversité des données.
Une stratégie bien pensée devrait harmoniser ces deux concepts pour créer un écosystème de données robuste et agile, répondant aux défis évolutifs de l’analyse et de la gestion des données.
