




Dans des systèmes informatiques complexes d’entreprises, l’automatisation des tâches répétitives est cruciale pour éviter les erreurs humaines. Ainsi, il faut commencer par automatiser les tâches manuelles fastidieuses, en commençant petit, selon l’expertise des équipes et le temps disponible. L’automatisation réduit la dette technique, donc il est important d’accorder du temps aux équipes pour ce travail. L’intégration continue est l’une des pratiques essentielles de l’automatisation logicielle.

Qu’est-ce qu’un système informatique ?
Le « système informatique » est un système automatisé qui utilise des outils informatiques et électroniques pour stocker, traiter et récupérer des données dans le cadre de processus complexes. Il fait partie des « systèmes d’information« , qui sont organisés autour du traitement de divers types de données. Il est important de noter que tous les systèmes d’information ne sont pas nécessairement des systèmes informatiques, et ils ne sont pas tous numériques, automatisés ou électroniques. Un système informatique se compose de trois éléments clés : le matériel (ordinateur, écran, clavier, etc.), le logiciel (programmes informatiques, applications) et l’élément humain (utilisateurs intervenant dans un réseau informatique).
Lorsque l’on parle d’automatisation des systèmes informatiques, cela peut concerner plusieurs pratiques telles que :
- L’Infrastructure as Code (IaC) ;
- L’Analyse de sécurité (SAST, DAST, IAST…) ;
- L’intégration continue (CI) ;
- Le déploiement continu (CD) ;
- etc.
Ici, nous aborderons tout ce qui est lié à la notion de « pipeline CI/CD » et à l’intégration continue (continuous integration en anglais).
I) Que signifie pipeline ci/cd ?
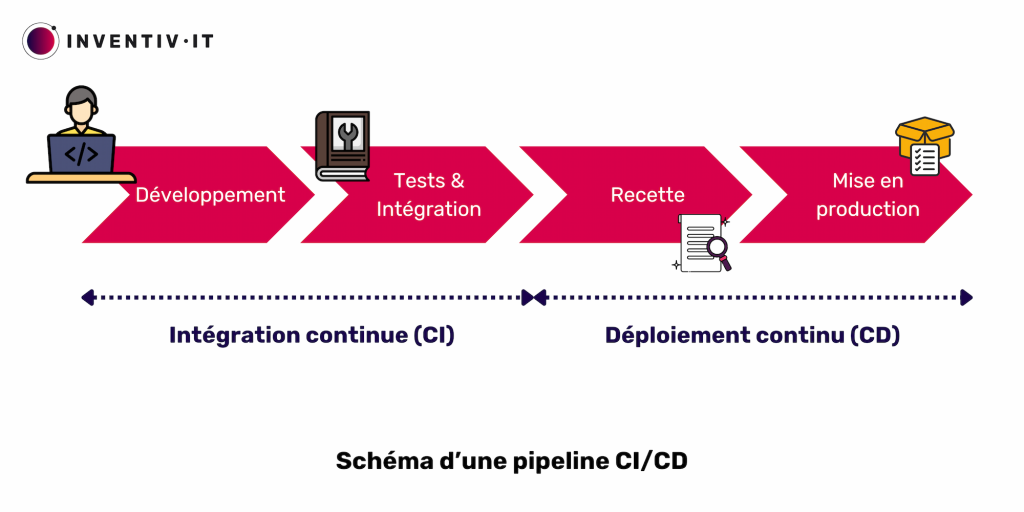
Historiquement, on déployait une application deux à trois fois par an, chaque fois avec de nouvelles fonctionnalités. Cependant, les délais entre mises à jour majeures étaient jugés trop longs dans le contexte concurrentiel actuel. La séquentialité entre les équipes de développement et les équipes d’exploitation explique en partie ce délai. Chaque étape du déploiement (développement, tests et intégration, recette, mise en production) est gérée par une équipe distincte, nécessitant une coordination et une synchronisation qui rallongent le processus.
La création d’un pipeline CI/CD automatise les étapes pour faciliter le développement jusqu’à la mise en production. Cette approche, incluant l‘intégration continue et le déploiement continu, augmente la fréquence de distribution des applications. Elle répond aux défis de l’intégration de nouveaux segments de code, souvent désignés comme « l’enfer de l’intégration ».
L’objectif global est d’assurer une automatisation constante et une surveillance tout au long du cycle de vie des applications, depuis les phases d’intégration et de test jusqu’à la distribution et au déploiement, rassemblées sous l’appellation « pipeline CI/CD« . Ces pratiques reposent sur une collaboration agile entre les équipes de développement et d’exploitation, intégrées dans des approches comme DevOps, DevSecOps ou l’ingénierie de fiabilité des sites (SRE).
L’intégration continue (CI) s’efforce ainsi d’automatiser les procédures du développement, tandis que le déploiement continu (CD) cherche à automatiser les étapes de déploiement.
Téléchargez le livre blanc sur la création d’une Usine Logicielle DevSecOps
II) Qu’est-ce que l’intégration continue (CI) ?
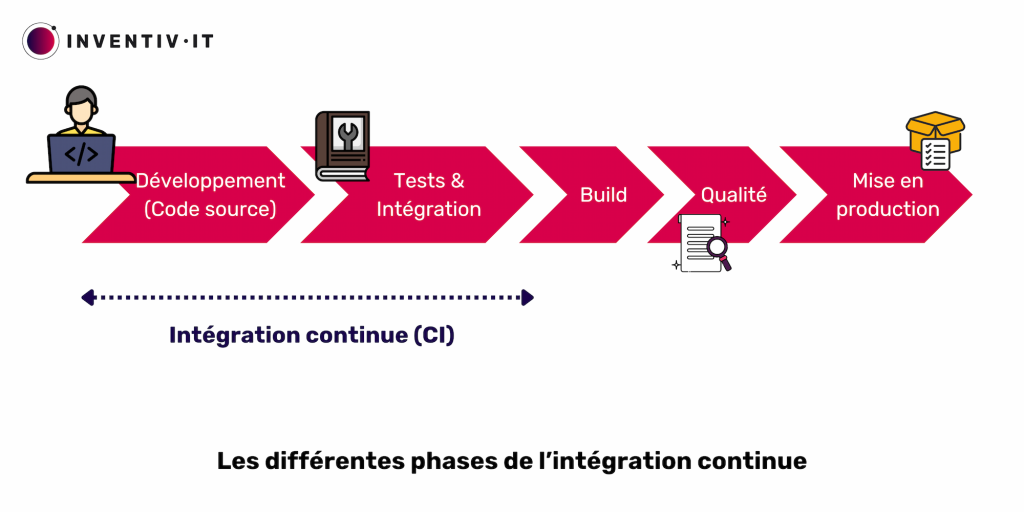
Deux étapes forment l‘intégration continue : la phase de build et la phase de tests.
a) Intégration continue : la phase de build
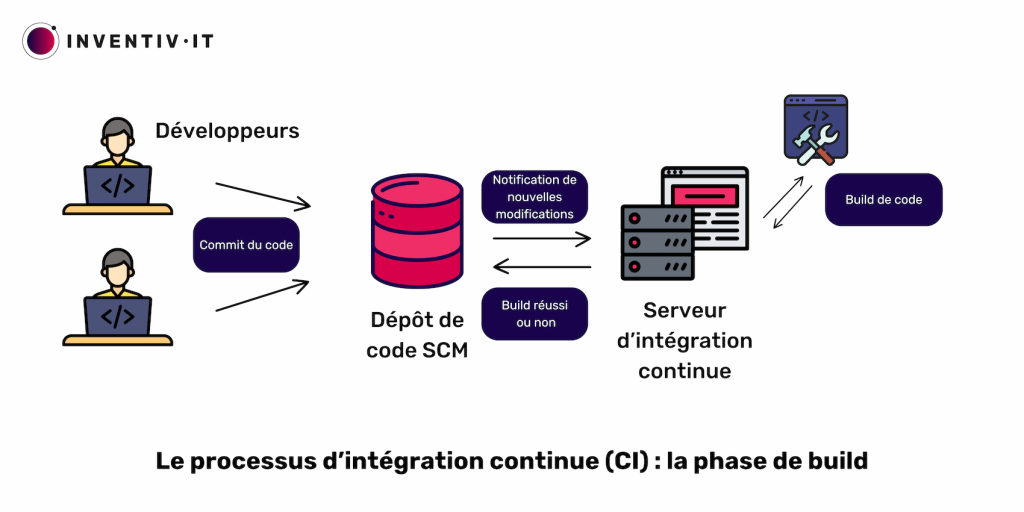
Les applications modernes comprennent de petits services indépendants, également appelés microservices. Chaque développeur travaillant simultanément sur différentes parties de l’application peut entraîner des conflits lorsque plusieurs développeurs apportent des modifications en même temps. Lorsqu’un développeur enregistre ses modifications en effectuant un commit du code, un outil de gestion de code source (SCM, pour Source Code Management) va centraliser progressivement ces modifications de code et gérer l’ensemble des évolutions. Des exemples populaires d’outils SCM sont Git et GitLab.
Ensuite, le serveur d’intégration récupère ce code. Ce serveur, composé de plusieurs services, utilise un service d’orchestration tel que Jenkins pour déclencher des actions lors de la détection de modifications dans le code source. En fonction du langage de programmation, Jenkins appelle un service chargé de réaliser la compilation, c’est-à-dire la création d’un build, une version exécutable de l’application.
Le serveur (comme Jenkins ou GitLab CI/CD) procède donc à la construction du code. La construction transforme le code source en fichiers exécutables utilisables sur ordinateur ou serveur. Pour certains langages, cette phase inclut la compilation, transformant les fichiers du code source en un format exécutable, souvent en langage machine ou en binaire.
Après la construction, le serveur d’intégration informe le dépôt du résultat (succès ou échec).
Découvrez le concept de déploiement continu
b) Intégration continue : la phase de tests
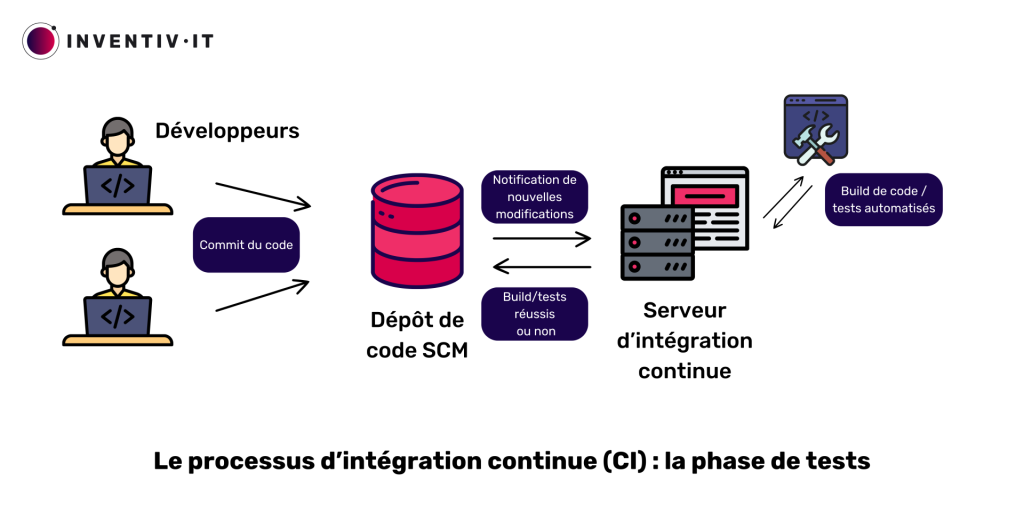
Après la construction réussie, le SCM effectue des tests rapides, vérifiant l’absence d’erreurs introduites dans le code source. Ces tests comprennent notamment :
- Les tests unitaires, développés par le programmeur, visant à valider le bon fonctionnement d’une fonction spécifique ;
- Les tests d’intégration système évaluent le fonctionnement global de l’application ;
- Les contrôles qualité comprennent la vérification de la qualité du code via des services comme Sonarqube ;
- Un contrôle qui s’assure que les dépendances sont sans failles connues, avec des outils tels que JFrog Xray ;
- Les tests d’APi, de compatibilité…
Si cette phase de tests identifie un problème, le processus CI/CD s’interrompt, et les développeurs en sont informés. En cas de réussite des tests automatisés, le processus valide et archive le nouveau build dans un « repository » (dépôt d’artefacts en français). Le build étant centralisé et versionné dans le dépôt, il est ainsi prêt pour le déploiement. C’est l’étape suivante, appelée « déploiement continu » que l’on abordera dans un prochain article !
Ainsi, l’intégration continue (CI) est une pratique de développement logiciel qui implique l’automatisation de vérifications à chaque modification du code. Ces vérifications couvrent la conformité, la qualité du logiciel et les prérequis pour la mise en production. La CI contribue à réduire la dette technique et facilite le déploiement en garantissant le respect des normes établies par les équipes DevSecOps. Il est également courant d’entendre parler de pipeline d’intégration continue, qui accompagne d’autres termes dans l’univers des technologies de CI/CD.
