




Aujourd’hui, le déploiement continu est essentiel pour rendre les processus automatiques et conserver un avantage concurrentiel pour réduire le travail manuel, et est couplé à la livraison continue, ainsi qu’à des tests automatisés pour réduire les erreurs humaines et accélérer le cycle de mise en production. L’instauration de stratégies de rollback efficaces renforce la résilience des systèmes en cas d’échec. Cet article examine l’importance croissante et les vrais bénéfices du déploiement continu pour les entreprises modernes.

I) Qu’est-ce que le déploiement continu ?
Le déploiement continu, également connu sous le nom de CD (Continuous Deployment ou CD en anglais), représente une pratique intégrée au sein de l’approche DevOps et DevSecOps. Son objectif est d’automatiser les processus d’administration, de déploiement et de mise à jour des logiciels en production à travers une chaîne de déploiement continu. Cette automatisation permet de déclencher des actions prédéfinies, assurant ainsi des opérations prévisibles, traçables et réplicables. Ainsi, le déploiement continu accélère l’offre de nouvelles fonctionnalités tout en minimisant les risques et les interventions manuelles des administrateurs.
Qu’est-ce qu’une chaîne de déploiement continu ?
Les chaînes de déploiement continu (CD) sont similaires aux chaînes d’intégration continue (CI) mais peuvent nécessiter des paramètres spécifiques comme des variables d’environnement. Elles automatisent le processus de mise à jour en production du logiciel, y compris les tests de validation, et permettent un suivi visuel de l’état du déploiement via des outils tels que ArgoCD, Flux, Spinnaker ou Jenkins X. En outre, les CD ne se limitent pas au déploiement, mais peuvent également servir à superviser le logiciel.
a) Le principe du déploiement continu
Le déploiement continu en production a été inventé par Timothy Fitz en 2009, à l’issue de déploiements excessifs par une société (avec des mises en production supérieures à 50 fois par jour).
Dans la pratique du déploiement continu, tout comme pour la livraison continue, le principe est de prendre un nouveau code et de le déplacer le plus rapidement possible en production.
Le déploiement continu consiste ainsi à prendre le code et à le construire (étape du build) avec un outil d’intégration continue. Puis, le code va être déployé dans un ou plusieurs environnements de tests (étapes d’assurance qualité et de pré-production -staging-) puis il passera en production. Toutes les étapes du déploiement continu sont automatisées. Nous vous détaillons, ci-après, les différentes étapes du déploiement continu.
En quoi consiste la phase de Build ?
La phase de build est une étape du processus de développement logiciel où le code source est transformé en fichiers exécutables utilisables sur un ordinateur ou un serveur. Elle inclut souvent la compilation, qui convertit les fichiers du code source en un format exécutable, tel que le langage machine ou le binaire.
En ce qui concerne le déploiement d’une application sur un environnement, il existe plusieurs options. Traditionnellement, le déploiement se fait sur un serveur physique ou virtuel à l’aide d’un script ou d’un outil automatisé. Pour des applications plus modernes, le déploiement via des conteneurs avec une image Docker est de plus en plus courant. Pour les tests, il est même envisageable d’utiliser l’infrastructure as code (IAC) pour créer dynamiquement un environnement. Toutes ces options reposent sur des fichiers de configuration pour fonctionner.
Téléchargez le livre blanc sur la création d’une Usine Logicielle DevSecOps
b) Les différentes étapes du déploiement continu
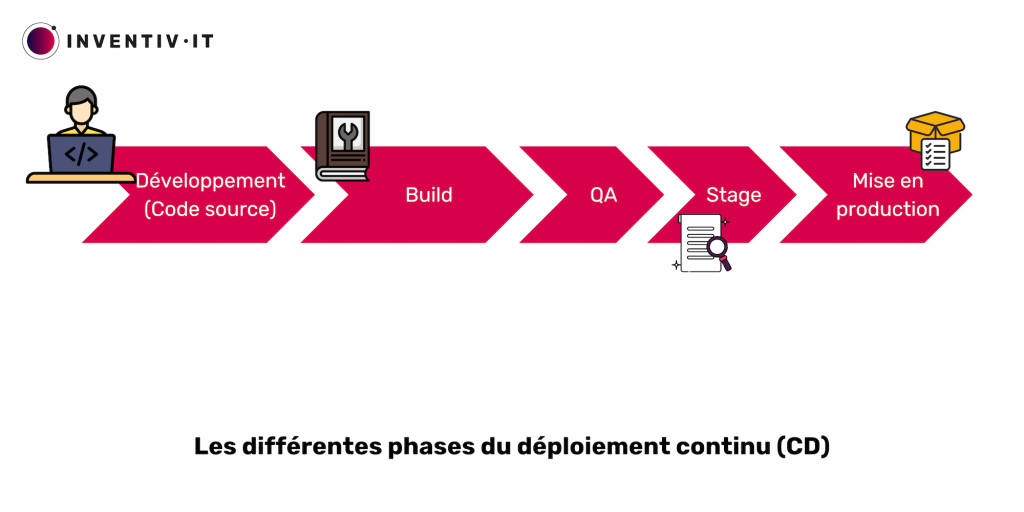
En détails, voilà ce que cela donne :
- On a un code, pas un logiciel, le but est donc de le transformer en logiciel grâce au serveur d’intégration continue : c’est l’étape de construction (build).
- Une fois le logiciel obtenu, on pourrait simplement le déployer en production. En réalité, on va faire passer au logiciel une série de tests. La plupart des entreprises disposent de deux à cinq environnements de tests, que l’on nomme « QA » et « Stage » (pré-production). Ces derniers permettent d’avoir un code dans un état releasable, prêt à être déployé et pour une mise en production (mais pas encore déployé), et ce, tout au long de son cycle de vie.
- Notre logiciel est donc passé dans l’environnement d’assurance qualité, puis dans l’environnement de test « stage » puis mis en production.
En quoi le déploiement est-il automatisé ?
Il existe un déclencheur qui indique au serveur de build que le nouveau code est prêt. Il fait alors automatiquement une construction. Cela déclenche un déploiement vers QA qui déclenche ensuite automatiquement les premiers tests. Si ceux-ci réussissent, cela passe automatiquement au déclenchement des autres tests, puis à la mise en production. C’est pour cela que qu’on dit que le déploiement est « continu » en production.
NB : en cas de problème lors de la production du logiciel ou de l’application (des serveurs qui fonctionnent mal…), il est possible de retourner en arrière dans la chaîne de déploiement continu pour corriger le code (rollback). Nous parlons de ces pratiques dans la partie 3 de l’article. Cette approche de déploiement continu est extrême, car aucune intervention humaine n’est requise de l’écriture du code à la production.
II) le déploiement continu vs le continuous delivery
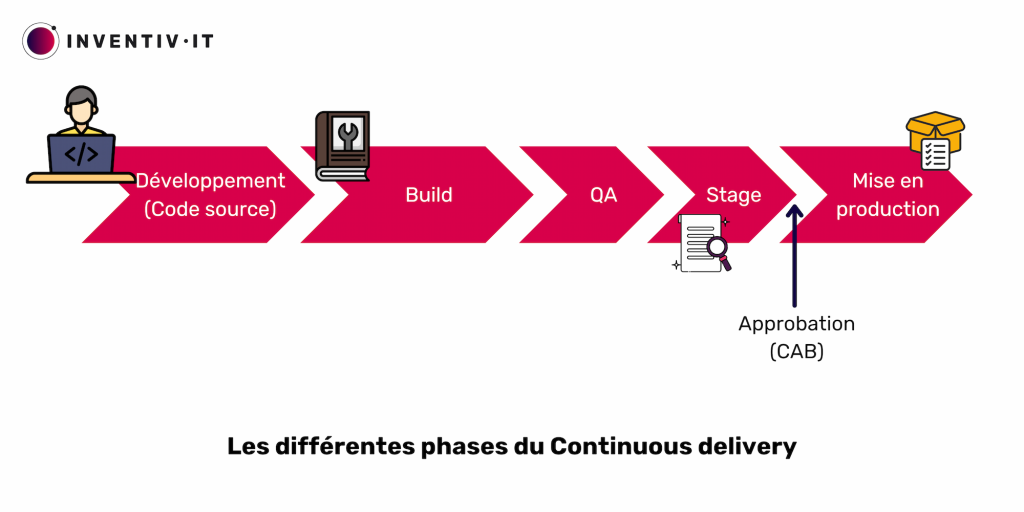
Comme vu précédemment, le déploiement continu est donc quelque chose de « risqué » de part l’automatisation de l’ensemble de la pipeline CI/CD. Beaucoup d’organisations manquent de ressources et d’approbation réglementaire pour des mises en production sans contrôle préalable. Ces dernières vont alors avoir besoin d’une vérification humaine, entre le passage du dernier environnement de tests à la production.
Et c’est là que l’on va distinguer le Continuous Delivery (ou livraison/distribution continue en français) du déploiement continu. Tout comme pour le Continuous Deployment, la livraison continue consiste à automatiser la chaîne du commit du code jusqu’à la fin des tests. Mais, la différence est que l’on aura un point de vérification à l’issue des tests, avec une approbation humaine de si l’on produit ou non le logiciel (historiquement via le Comité consultatif sur les modifications (CAB)).
Automatiser au maximum tout en conservant la décision finale de mise en production, voilà le principe de la distribution continue.
Le Continuous Delivery assure ainsi un retour d’information rapide en fournissant des feedbacks automatiques sur les environnements de préproduction et de production. Il maintient le logiciel dans un état prêt à être publié et déployé même pendant le développement de nouvelles fonctionnalités. Un pipeline de déploiement à la demande est essentiel pour maximiser l’efficacité et minimiser les risques. Les entreprises peuvent opter pour le déploiement continu ou la livraison continue pour des mises en production rapides et sécurisées.
Automatisation logicielle : pipeline CI/CD et Intégration Continue
III) Les bonnes pratiques du déploiement continu : tests automatisés et rollback

a) L’importance des tests automatisés dans le déploiement continu
Comme vu plus haut, le déploiement continu est principalement caractérisé par la réalisation de tests automatisés. De nouveaux tests automatisés sont effectués à chaque livraison de l’application jusqu’à la production.
- On a par exemple des tests automatisés dits « de recette » : on utilise pour cela un outil comme Selenium qui permet de dérouler des scénarios complets de tests d’une application.
- Ensuite, on a des tests qui permettent de tester l’écosystème applicatif complet (avec des référentiels, des applications en amont et en aval…) : ici on peut utiliser l’outil UFT (Unified Functional Testing).
- On a également des tests de charge et de performance pour vérifier que les nouvelles fonctionnalités ne dégradent pas les temps d’accès et d’exécution de l’application et qu’elle continue bien de supporter un nombre défini d’utilisateurs simultanés.
Pour l’ensemble des tests effectués, on va à la fois contrôler les nouvelles fonctionnalités mais aussi les non régressions (le test de non régression permettra de valider que la mise en ligne d’une nouvelle fonctionnalité d’un logiciel n’impactera pas les fonctionnalités déjà existantes). On identifie alors, pour chaque type de test, des scénarios importants qui vont être revérifiés à chaque fois.
Les tests automatisés sont donc primordiaux dans une chaîne CI/CD. L’objectif est de détecter les erreurs dès que possible dans le processus pour les rectifier rapidement. Avec des itérations plus rapides, les erreurs sont mieux gérées, réduisant leur impact et facilitant leur détection et leur résolution.
b) Les techniques de rollback : méthodes blue/green et Canary Releases
Une autre condition indispensable à un bon déploiement continu est de pouvoir effectuer un retour en arrière (rollback) de manière rapide lors de dysfonctionnement du déploiement d’une nouvelle version de logiciel. Il existe deux techniques de rollback : la méthode « Blue/Green » et la méthode « Canary Releases« .
1) La méthode Blue/Green
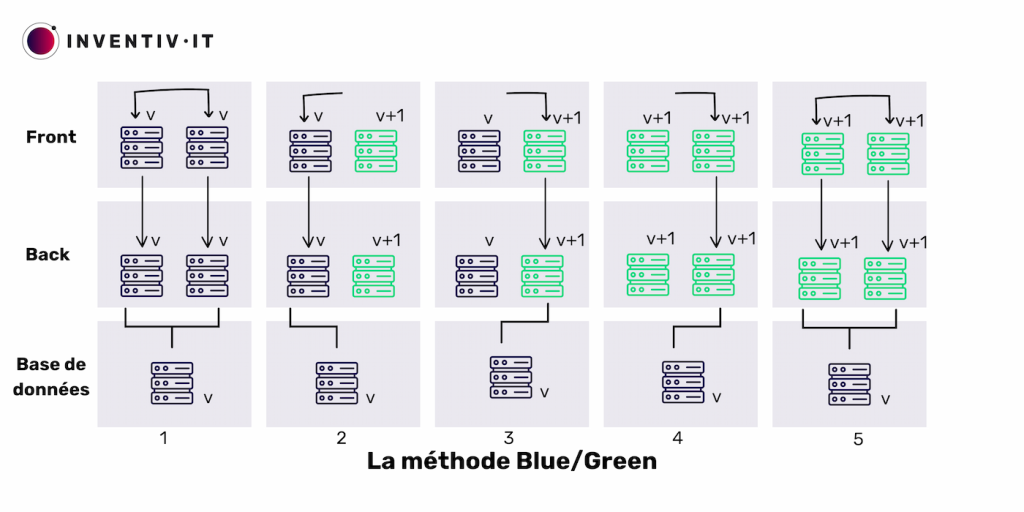
La méthode Blue/Green est une approche de déploiement sans interruption de service, idéale pour les applications nécessitant une disponibilité continue.
Elle déploie une nouvelle version (green) sur certains serveurs tout en maintenant l’actuelle (blue) sur d’autres. Le processus se déroule en plusieurs étapes. La nouvelle version est déployée sur une chaîne tandis que l’autre reste active, puis le trafic est basculé progressivement vers la nouvelle version. Si des problèmes surviennent, un retour en arrière peut être effectué facilement. Cette méthode permet d’assurer la disponibilité du service tout en minimisant les risques. Elle peut être automatisée pour une gestion plus efficace des déploiements.
2) La méthode Canary Releases
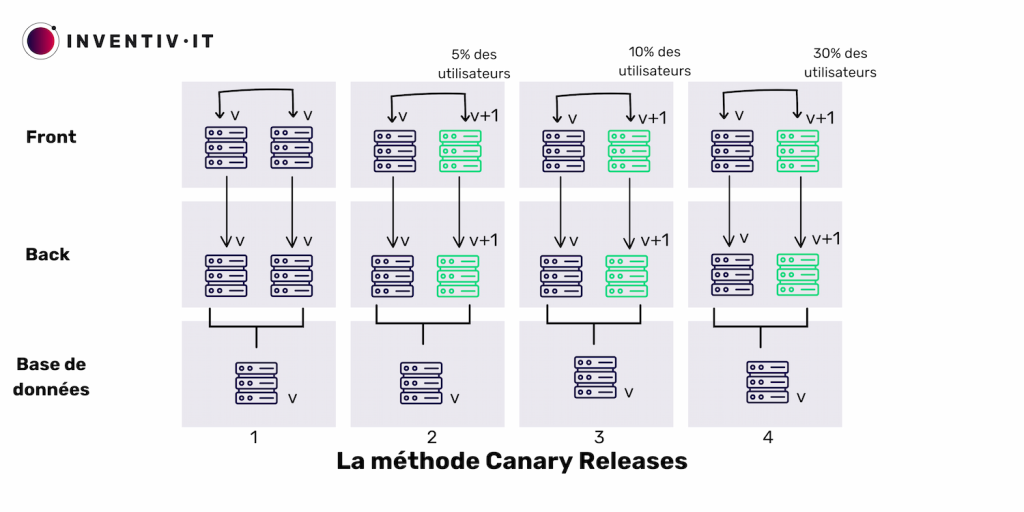
La méthode Canary Releases, semblable au Blue/Green, implique de déployer une nouvelle version de l’application sur une partie des serveurs tout en maintenant la version actuelle sur d’autres.
Avec cette approche, seuls quelques utilisateurs accèdent à la nouvelle version, tandis que les autres utilisent l’ancienne. Facebook et Google utilisent fréquemment cette méthode. Ils testent d’abord la nouvelle version sur un petit groupe d’utilisateurs avant de la déployer à grande échelle.
Le trafic bascule progressivement vers la nouvelle version, en commençant par une petite proportion d’utilisateurs et en augmentant progressivement. En cas de dysfonctionnement, nous réacheminons tout le trafic vers la version précédente pour un retour en arrière.
Outre les tests automatisés et les méthodes de rollback, il est important d’avoir une infrastructure de qualité, c’est-à-dire sous surveillance constante, avec des alertes configurées pour détecter tout dysfonctionnement éventuel.
En résumé, le déploiement continu facilite et accélère le processus de développement, de test et de mise en production des nouvelles fonctionnalités. Il offre la possibilité aux développeurs de voir leurs évolutions rapidement opérationnelles. N’hésitez pas à consulter notre article sur les pipelines CI/CD et l’intégration continue pour compléter ces connaissances !
