




Dans cet article, nous explorerons ce qu’est le Data Mesh, ses principes fondamentaux, pourquoi il est avantageux, comment l’implémenter, ainsi que les défis et l’avenir de cette technologie.
Mais avant de vous parler du data mesh, nous allons faire un bref rappel sur les principales tendances de la data architecture en 2024.
I. Quelles sont les Tendances de l’architecture des données en 2024 ?
L’architecture des données est un domaine en perpétuelle évolution, façonné par des tendances innovantes qui redéfinissent la manière dont les entreprises collectent, stockent et exploitent leurs données. En 2024, plusieurs courants majeurs se distinguent, orientant les stratégies de gestion des données vers de nouveaux horizons. Parmi ces tendances, la montée en puissance du data mesh se révèle particulièrement révolutionnaire.
Tout d’abord, l’émergence de l’intelligence artificielle (IA) et de la GenAI continue de transformer la data architecture, en automatisant l’analyse des données et en fournissant des insights plus rapidement et avec une précision accrue.
Ensuite, la transition vers le cloud et les architectures hybrides gagne du terrain, offrant aux entreprises une flexibilité et une scalabilité sans précédent.
Enfin, l’évolution des data lakes, qui deviennent plus sophistiqués et mieux intégrés, permet une gestion plus efficace et une accessibilité optimisée des données.
Cependant, parmi ces tendances, le maillage de données se distingue comme une approche innovante et décentralisée de la gestion des données. Quels sont les enjeux et défis de cette approche ? Nous vous expliquons tout.
Téléchargez le livre blanc sur le Data Mesh
II. Qu’est-ce qu’un data mesh ?
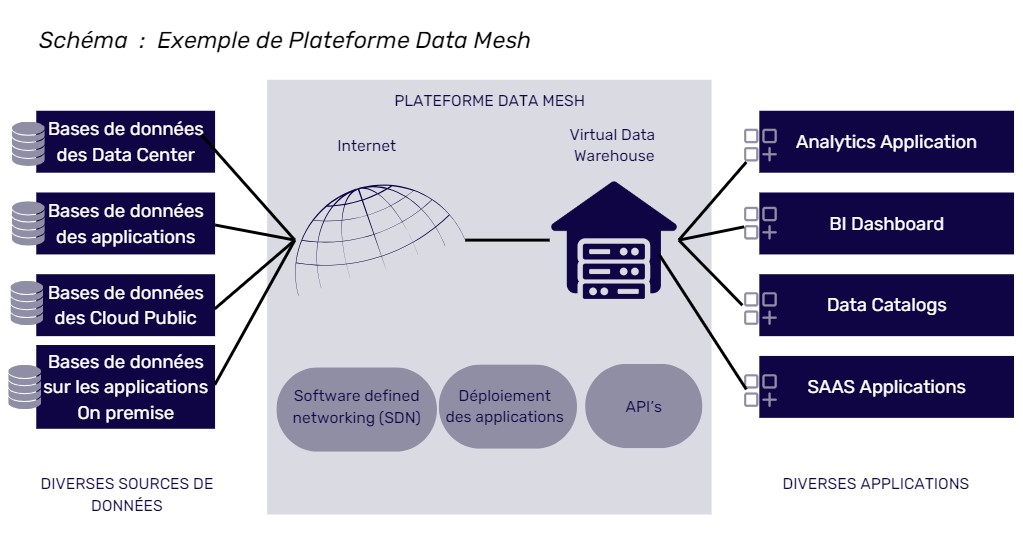
Le data mesh ou maillage de données est une approche novatrice de la gestion des données. C’est une architecture de données qui vise à résoudre les problèmes traditionnels liés à la centralisation des données.
Zhamak Dehghani, responsable de l’architecture au sein de ThoughtWorks a popularisé ce concept lors d’une conférence en 2018. Le data mesh repose sur l’idée que les données sont mieux gérées de manière distribuée, au lieu d’être centralisées dans un seul entrepôt de données.
Au cœur du maillage de données se trouve l’idée de la décentralisation des données. En effet, plutôt que de stocker toute la data dans un seul endroit, le data mesh propose de la distribuer de manière efficace à travers toute l’entreprise. Autrement dit, chaque équipe ou département est responsable de ses propres données et les gèrent de manière autonome.
III. Pourquoi le data mesh?
1. Les limites des architectures traditionnelles
Les architectures de données traditionnelles, souvent centralisées, présentent de nombreuses limitations. Elles peuvent devenir des goulots d’étranglement, ralentissant l’accès aux données et limitant la capacité des équipes à réagir rapidement aux besoins du marché.
De plus, la centralisation des données peut entraîner des problèmes de qualité et de gouvernance des données. Car, les équipes locales ont moins de contrôle sur leurs propres informations.
2. Les avantages du data mesh
Le maillage de données est important pour plusieurs raisons à savoir : la résolution des problèmes de performance, la collaboration au sein de l’entreprise, la gestion des données massives.
Tout d’abord, il permet de résoudre les problèmes de performance liés à la centralisation des données. Les données stockées au même endroit peuvent entraîner des problèmes de latence et de surcharge qui peuvent affecter la performance de vos applications et services.
En outre, le maillage de données favorise la collaboration au sein de l’entreprise. Il encourage à cet effet chaque équipe à gérer ses propres données. En effet, le Data Mesh incite les équipes à partager leurs données avec d’autres. Cette culture favorise l’innovation et la collaboration au sein des organisations.
Enfin, le data mesh répond aux besoins des entreprises en matière de données. En effet, les structures d’aujourd’hui, notamment les grandes entreprises génèrent des quantités massives de données. Ainsi, il est important de disposer d’une approche de gestion des données qui puisse évoluer avec elles. Le maillage de données permet de faire évoluer le management des données de manière flexible, en s’adaptant aux besoins changeants de l’entreprise.
Pour mieux comprendre l’approche et la distinguer des autres architectures traditionnelles, nous vous proposons de voir la différence entre un data mesh, un data lake, et autres architectures classiques.
IV. Data mesh vs data lake, data warehouse et data mart
| Approche | Définition |
| Data Mesh | Décentralise la gestion des données. Chaque département gère ses propres données comme des produits |
| Data Lake | Grand dépôt de données brutes non transformées |
| Data Warehouse | Référentiel centralisé de données structurées, optimisées pour l’analyse |
| Data Mart | Sous-ensemble d’un data warehouse pour des besoins spécifiques |
1. Data Mesh :
- Définition : Le data mesh est une approche décentralisée de la gestion des données où les données sont gérées par des équipes indépendantes en fonction de leurs domaines spécifiques (par exemple, ventes, marketing, etc.).
- Objectif : L’objectif est de réduire les goulets d’étranglement et d’améliorer l’évolutivité et l’agilité en déléguant la responsabilité des données aux équipes qui en ont la connaissance et l’expertise les plus directes.
- Caractéristiques : Cette architecture favorise l’autonomie des équipes, la gestion de la qualité des données, la sécurité et la conformité.
2. Data Lake :
- Définition : Un data lake est un référentiel de stockage qui peut contenir de grandes quantités de données brutes dans leur format natif, qu’elles soient structurées, semi-structurées ou non structurées.
- Objectif : Permettre le stockage flexible de grandes masses de données provenant de diverses sources, prêtes à être analysées ou transformées.
- Caractéristiques : Les données sont stockées de manière peu coûteuse et peuvent être explorées de différentes manières. Toutefois, sans une gouvernance de données appropriée, un data lake peut devenir un « data swamp » (marécage de données), rendant les données difficiles à utiliser.
3. Data Warehouse
- Définition : Un data warehouse est un système de stockage de données conçu pour l’analyse et les requêtes de données. Les données sont généralement transformées, nettoyées et structurées dans cette architecture.
- Objectif : Faciliter la prise de décision stratégique en fournissant un accès rapide à des données historiques et bien structurées.
- Caractéristiques : Les data warehouses sont optimisés pour des requêtes complexes et des rapports analytiques. Ils nécessitent un processus ETL (Extract, Transform, Load) rigoureux pour intégrer les données.
4. Data Mart
- Définition : Un data mart est une sous-section d’un data warehouse, orientée vers une ligne d’affaires ou une équipe spécifique (par exemple, finance, marketing).
- Objectif : Fournir un accès rapide et spécialisé aux données pertinentes pour des utilisateurs ou des équipes spécifiques.
- Caractéristiques : Un data mart contient un sous-ensemble des données du data warehouse et est conçu pour répondre aux besoins particuliers de ses utilisateurs.
V. quels sont les principes fondamentaux du data mesh ?
Le Data Mesh repose sur quatre piliers clés définissant son approche décentralisée et axée sur les domaines de gestion des données.
1. Propriété des données par domaine
Dans ce modèle, on délègue la responsabilité aux équipes qui connaissent le mieux leur domaine spécifique. En effet, chaque département au sein de l’organisation est responsable de la gestion, de la qualité et de la livraison de ses propres données en tant que produit.
2. Infrastructure de données en libre-service
Le Data Mesh met en avant l’idée d’une infrastructure en libre-service. Dans celle-ci les équipes peuvent facilement accéder et utiliser les outils et ressources nécessaires pour gérer leurs données. Cela inclut des plateformes de stockage, des outils d’analyse, et des systèmes de gestion des métadonnées. Grâce à une infrastructure en libre-service, les équipes peuvent travailler de manière plus autonome et réactive.
3. Les données en tant que produit
Plutôt que de traiter les données comme un sous-produit de projets, le maillage de données propose de considérer la data architecture comme un produit en soi.
Cela implique une approche continue et itérative de la gestion des données, avec des mises à jour régulières et une maintenance proactive. Cette perspective produit permet d’assurer une valeur continue et d’éviter les inefficacités des projets ponctuels.
4. Gouvernance fédérée par conception
Le Data Mesh intègre une gouvernance fédérée. Cette gouvernance combine les avantages de la centralisation et de la décentralisation des données. L’organisation définit les standards de gouvernance. Par ailleurs, leur application est déléguée aux domaines.
Cette approche permet de maintenir une cohérence globale tout en offrant la flexibilité nécessaire pour répondre aux besoins spécifiques de chaque domaine. Toute l’organisation applique de manière cohérente les principes de sécurité, de conformité, et de gestion de la qualité des données.
VI. Comment mettre en place un data mesh ?
La mise en place d’un data mesh est une démarche structurée qui nécessite une transformation organisationnelle et technique. Pour ce faire, nous vous proposons 4 étapes clés pour mettre en place un data mesh :
1. Évaluation des besoins de l’entreprise
La première étape pour implémenter un Data Mesh est d’évaluer les besoins spécifiques de l’entreprise. Elle inclut entre autre : une analyse des flux de données actuels, des défis rencontrés et des objectifs à long terme. L’évaluation de besoins permet de définir une stratégie adaptée à l’organisation.
2. Structuration des équipes par domaines
Ensuite, il faudrait structurer les équipes par domaines de données. Chaque domaine doit avoir une équipe dédiée responsable de la gestion, de la qualité et de la sécurité de ses données. Cette structuration facilite la décentralisation et améliore la réactivité.
3. Choix des outils et technologies
En outre, il faudrait choisir les outils et technologies du data mesh. Le choix des outils et technologies est également essentiel pour la réussite d’un Data Mesh. Il faut sélectionner des solutions qui supportent la décentralisation, comme des plateformes de stockage en cloud, des outils d’intégration de données, et des systèmes de gestion des métadonnées.
4. Stratégies de gouvernance et de sécurité
Enfin, il est important de mettre en place des stratégies de gouvernance des données et de sécurité robustes. Il s’agit de définir des standards communs, d’établir des protocoles de sécurité, et de former des équipes sur les meilleures pratiques de la gouvernance.
VII. Défis et considérations
Mettre en place un data mesh s’accompagne de plusieurs défis que les organisations doivent anticiper et gérer efficacement. Voici les principaux défis auxquels vous pourriez faire face lors de la mise en œuvre du maillage des données :
1. Complexité de la mise en œuvre
La transition vers le maillage de données n’est pas qu’une simple question de technologie. En effet, elle requiert aussi de transformation profonde des processus et des structures organisationnelles. Les défis techniques peuvent être :
- Intégration des systèmes existants : La migration des architectures centralisées vers une architecture décentralisée peut nécessiter une majeure refonte des systèmes existants.
- Interopérabilité des données : Assurer que les différents domaines puissent échanger des données de manière fluide et cohérente.
- Infrastructure en libre-service : La mise en place d’une infrastructure de données en libre-service nécessite de grands investissements en termes de temps, d’argent et de compétences.
2. Transformation culturelle et organisationnelle
Mettre en place un Data Mesh implique un changement de mentalité et de culture au sein de l’organisation :
- Responsabilisation des équipes : Les équipes de chaque domaine doivent accepter et gérer la responsabilité de leurs propres données.
- Collaboration inter-domaine : Favoriser une collaboration efficace entre les différents domaines pour éviter les silos de données tout en respectant l’autonomie de chaque domaine.
- Formation et compétences : Les employés doivent acquérir de nouvelles compétences en matière de gestion et de gouvernance des données.
3. Gestion du changement
La mise en place d’un Data Mesh nécessite une gestion du changement rigoureuse pour minimiser les perturbations et assurer une transition en douceur :
- Communication claire : Expliquer clairement les raisons du changement et les avantages attendus pour obtenir l’adhésion des parties prenantes.
- Planification progressive : Déployer le Data Mesh de manière itérative et progressive pour permettre une adaptation en douceur.
- Support et assistance : Fournir un support continu et des ressources pour aider les équipes à s’adapter aux nouveaux processus et outils.
4. Sécurité et conformité
Un autre défi important à ne pas négliger : assurer la sécurité des données et la conformité aux réglementations :
- Protection des données : Mettre en place des mécanismes robustes de protection des données pour prévenir les violations de sécurité.
- Conformité réglementaire : Maintenir la conformité avec les réglementations locales et internationales, telles que le RGPD, en assurant une gestion adéquate des accès et des permissions.
- Gouvernance des données : Établir une gouvernance des données efficace incluant des politiques et des standards clairs pour chaque domaine, tout en maintenant une vue d’ensemble cohérente au niveau de l’organisation.
ce qu’il faudrait retenir sur le data mesh
Le maillage de données révolutionne la gestion des données en décentralisant la responsabilité des données aux différentes équipes de l’entreprise. Il offre ainsi flexibilité, scalabilité et agilité. Bien que mettre en œuvre un data mesh pose des défis techniques et organisationnels, les avantages en termes de qualité des données et de réactivité des équipes en font un investissement précieux. Adopter le Data Mesh permet aux entreprises de mieux gérer leurs masses de données.
