




Toute stratégie data repose essentiellement sur la gouvernance des données. Pourtant, de nombreuses entreprises commettent encore des erreurs qui compromettent la qualité des données. Et donc, l’efficacité de leurs projets d’IA ou automatisés.
Voici ce que nous dit une étude menée par Precisely au premier semestre 2024 (elle interroge 565 professionnels des données).
- Seulement 12% pensent que la qualité de leurs données est suffisante pour soutenir des initiatives en matière d’IA.
- 67% des entreprises déclarent ne pas avoir confiance aux données leur permettant de prendre des décisions.
Quand on leur demande sur le principal obstacle à l’adoption de l’IA, 62% des professionnels répondent que c’est : le manque de gouvernance des données.
Dans cet article, découvrez les 4 erreurs les plus courantes en matière de gouvernance des données, et surtout, comment les éviter.
Téléchargez le livre blanc sur la data governance & automatisation
Erreur 1 : Confondre gouvernance et conformité
Certaines entreprises confondent gouvernance et conformité. En effet, elles pensent immédiatement RGPD, ISO 2700, audit interne ou obligations réglementaires. Résultat : elles mettent en œuvre une gouvernance axée uniquement sur la conformité juridique.
Le problème est que ces politiques de gouvernance sont peu opérationnelles, rarement partagées par les équipes métiers et dissociées des usages quotidiens de la donnée.
Par ailleurs, d’autres entreprises détachent la conformité de la gouvernance globale. En effet, 60 % des utilisateurs des solutions GRC gèrent la conformité manuellement via des feuilles de calcul (Coalfire compliance Report 2023).
Quelle est la conséquence majeure ? Les projets d’automatisation ou de pilotage deviennent difficiles à fiabiliser. Car la gouvernance ne parle ni aux métiers, ni à la tech.
Solution : replacer la valeur métier au cœur de la gouvernance
La gouvernance des données doit être vécue comme un accélérateur stratégique. Elle doit répondre à la question suivante : « comment mieux exploiter nos données pour automatiser, décider,… en toute confiance ? » . Il s’agit de :
- Définir les règles, partant des usages métiers
- Permettre la collaboration entre équipes IT et juridique dès la conception des politiques
- Intégrer la gouvernance dans les projets data et digitaux, pas comme un contrôle a posteriori, mais comme un socle dès le démarrage.
Erreur 2 : Ne pas désigner les rôles clairs
La qualité des données est floue si les rôles ne sont pas clairement définis : chacun pense que c’est à l’autre de corriger. Ainsi, cela occasionne un cumul d’erreurs. Le rapport d’O’reilly stipule que 56% des organisations sont confrontées à au moins un problème de qualité des données lié souvent à des processus mal définis ou à l’absence de gouvernance claire.
Solution : mettre en place un modèle de rôle
Pour une gouvernance des données efficace, les rôles doivent être bien définis, partagés et alignés sur les processus de l’entreprise.
Voici une répartition simple et robuste, inspirée du modèle RACI
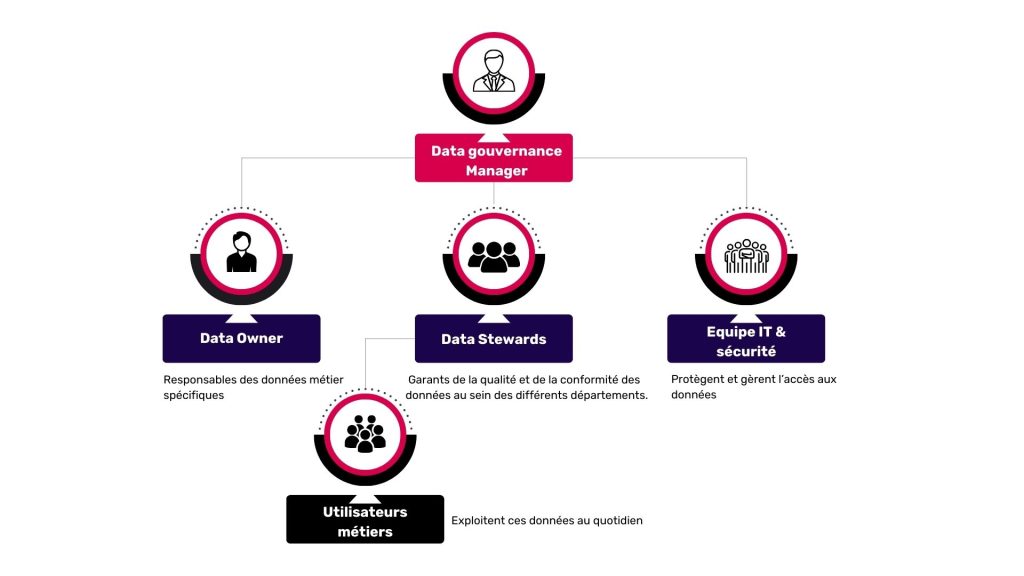
Une bonne répartition des rôles permet :
- D’avoir une responsabilité claire sur chaque type de donnée
- De détecter et de corriger rapidement les anomalies
- D’instaurer un climat de collaboration entre IT, métiers et data
- De mettre en place des projets data plus fluides, fiables et mieux acceptés
Quelques astuces :
- Cartographier les données critiques et associer un data owner à chacune d’entre elles
- Documenter les rôles et responsabilités dans un référentiel de gouvernance
- Intégrer la gouvernance dans les projets d’automatisation et d’IA, dès la phase de cadrage.
Téléchargez le livre blanc sur la data governance & automatisation
Erreur 3 : Lancer une initiative data sans cadre de qualité
La troisième erreur en gouvernance des données est de banaliser la qualité des données. En effet, les entreprises investissent de plus en plus dans l’automatisation, l’IA ou les CRM. Cependant, les résultats de leurs projets d’IA sont parfois sans appel : des modèles d’IA faussés, des processus automatisés qui tournent à vide, des tableaux de bords incohérents, etc.
Par exemple, en 2024, 80% des entreprises ont investi dans l’IA pour améliorer leur cashflow, selon l’analyse « Cash Maturity 2024 » de Sidetrade.
Par ailleurs, les projets d’IA ou d’automatisation sont parfois menés sans vérification de l’état réel des données sur lesquels ils vont reposer. Comme exemples concrets, nous pouvons citer PayPal qui a dû payer 7,7 millions de dollars d’amende en 2015 pour des incidents causés par le manque de contrôle des données. Nous pouvons aussi citer Samsung Securities qui a connu en 2018 des pertes de 105 milliards de dollars à cause d’une erreur de données.
Solution : intégrer un cadre de qualité dès le démarrage d’un projet data-driven
Evaluez la qualité des données en amont avant de lancer tout projet qui exploite les données.
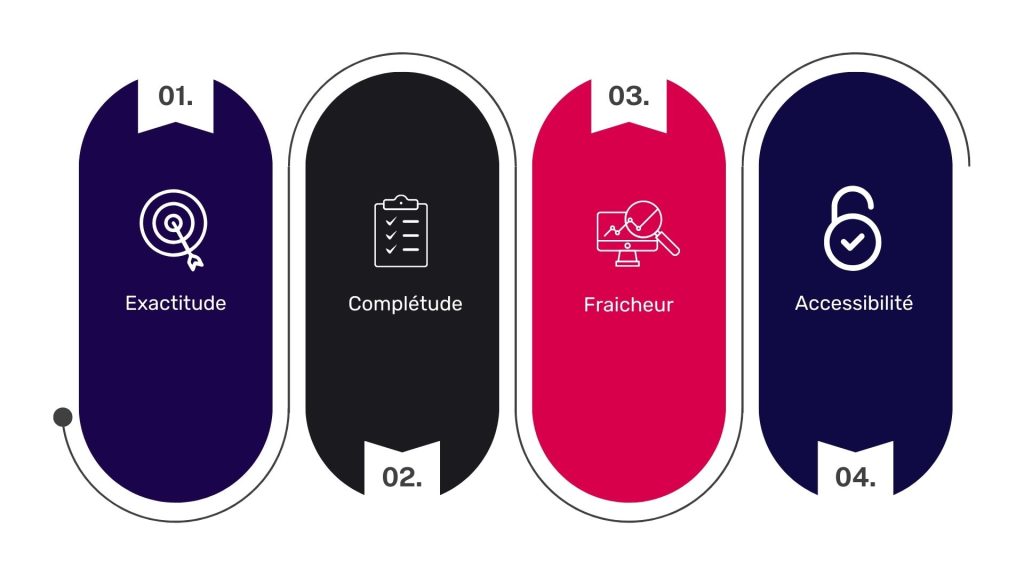
Diagnostiquez systématiquement ces quatre piliers de la qualité des données : exactitude, complétude, fraicheur et accessibilité.
Mettez en place des KPIs de qualité
Après avoir réalisé le diagnostic, suivez la qualité des données utilisées dans vos projets dans le temps. Ce suivi passe par des indicateurs comme :
- Le pourcentage de doublons détectés
- Le pourcentage de champs critiques renseignés
- Le taux d’erreurs post-import
- Le délai moyen de correction d’une anomalie
Intégrez ces KPIs dans vos outils de pilotage (tableaux de bord, alertes, scoring de qualité). Pour cela, nous vous recommandons les outils comme : Talend Data Quality, Informatica Data Quality, DataGalaxy.
N’hésitez pas à télécharger ce livre blanc pour en savoir plus sur les outils.
Erreur 4 : Ne pas documenter les règles de gestion des données
Les données récentes de l’Insee et d’Eurostat montrent qu’environ 25 % des entreprises de l’UE partagent des données avec leurs clients et fournisseurs. Mais ces données sont-elles documentées de façon formelle ? Une enquête de l’Agence française anticorruption révèle que 2/3 des entreprises déclarent recenser tous leurs tiers. Mais ce recensement est limité par le manque de ressources et la diversité des tiers.
Malgré la progression du partage des données, la documentation formelle, exhaustive et systématique de ces données reste minoritaire dans les entreprises.
Solution : formaliser, centraliser et partager les règles de gestion
Pour lutter contre le chaos information, la clé en un mot est : documentation. Il ne s’agit pas d’une documentation statique stockée dans un drive. Nous parlons ici d’un référentiel vivant qui soit collaboratif et accessible à tous.
Mettez en place les éléments suivants :
- Un data catalog partagé : c’est le socle de la gouvernance des données. Il récence, indexe et décrit les informations disponibles dans une entreprise, avec leurs métadonnées, leur fréquence de mise à jour, leurs propriétaires. Vous pouvez également lire cet article pour en savoir plus sur la mise en place d’un data catalog.
- Un glossaire métier commun : il s’agit d’un dictionnaire partagé des termes métiers techniques : « que signifie – churn dans le contexte de votre entreprise ? ». Ce glossaire évite les approximations et les malentendus.
- Des règles de gestions claires : documentez et alignez les règles de calcul, de validation, de transformation ou de filtrage.
Astuce : faites participer les métiers dans la construction du référentiel
La valeur d’un glossaire dépend de l’usage qu’on en fait et de sa compréhension. Impliquez les référents métiers dans la définition des règles et alignez-les avec les équipes data et IT.
