




I. Qu’est-ce que l’observabilité des données?
La data observability (observabilité des données) est la capacité d’une organisation à comprendre, contrôler, optimiser ses données en temps réel.
Les entreprises collectent de plus en plus des données massives dans leurs bases de données. Selon les chiffres de Médiamétrie en 2024 :
- La France compte 48,5 millions quotidiens
- 12,2 millions de Français utilisent les outils d’IA conversationnelle
- Les sites et apps de la grande distribution rassemblent 37,3 millions de visiteurs uniques mensuels.
Ce volume de données peut devenir pour votre entreprise un vrai casse-tête dans leur gestion, leur organisation, leur exploitation, leur analyse. En d’autres termes, exploiter les données n’est pas si simple car vous faites face à des données disparates, certaines pouvant se dégrader et devenir inexploitables.
L‘observabilité des données vous permet de reprendre le contrôle sur la fiabilité, l’accessibilité et la qualité des données.
Télécharger le livre blanc sur la data observability
II. À quoi sert la data observability ?
L’observabilité des données est un concept clef qui se concentre sur la visibilité et la compréhension des données dans un environnement informatique. Il s’agit d’une approche proactive qui vise à garantir la qualité des données.
Aussi, elle assure que les données de l’entreprise soient accessibles et exploitables pour les utilisateurs et les systèmes qui en dépendent. Ainsi, la data observability vous aide à prendre des décisions éclairées et à détecter les problèmes potentiels avant qu’ils ne deviennent critiques.
Au-delà d’une simple surveillance des données, la data observability vous permet d’analyser, d’optimiser et de sécuriser vos données en temps réel.
Vous vous demandez certainement comment l’observabilité des données optimise vos données en temps réel. Cela nous amène à évoquer ses différents outils.
III. Quels sont les outils de la data observability ?
L’observabilité des données s’appuie sur des outils de télémétrie continue. En effet, ce sont des outils utilisés dans le but surveiller et collecter des données sur les systèmes informatiques et les applications en temps réel.
Les outils de télémétrie continue permettent de capturer des métriques, des événements et des journaux à partir de différentes sources, puis de les analyser et de les visualiser pour obtenir une compréhension approfondie du comportement du système.
Voici cinq des principaux outils de télémétrie continue utilisés dans la data observability :
1. Sifflet
Sifflet surveille complètement vos données et vos métadonnées. L’outil a pour avantage principal son interactivité. En effet, il permet de manipuler les données en temps réel et d’expérimenter différentes analyses et visualisations.
En outre, Sifflet peut s’intégrer à d’autres outils comme : AWS, Microsoft Azure et Google Cloud Platform.
Par ailleurs, en raison de sa conception et de ses contraintes de mémoire, Sifflet peut avoir des difficultés à gérer de gros volumes de données. Ainsi, pour surmonter cette problématique, la plateforme se positionne en acteur proactif afin de permettre aux entreprises de détecter les anomalies et rendre plus fiable l’utilisation des données.
2. Prometheus :
Prometheus est un système open-source de surveillance et d’alerte basé sur la collecte de métriques. En effet, il permet de récupérer et de stocker des données temporelles sur les performances des applications et des infrastructures. L’outil est idéal pour surveiller la santé de vos systèmes et applications.
Aussi, il garantit une expérience utilisateur de qualité pour vos utilisateurs finaux.
Par conséquent, tout comme Sifflet, Prometheus a une capacité limitée de stockage de données. Par défaut, la solution d’intégration stocke toutes les métriques collectées en mémoire. Cela signifie que la quantité de données qu’il peut gérer est limitée par la mémoire disponible sur le serveur.
Si le flux de données dépasse cette limite, il peut entraîner une perte de données ou un impact sur les performances du système d’information.
Pour pallier à cette limite, Prometheus propose des options de stockage à long terme, telles que l’intégration avec d’autres systèmes de stockage comme Thanos. Cependant, la configuration et la gestion de ces options peuvent être complexes et nécessitent une expertise supplémentaire.
3. Grafana :
Grafana une plateforme open-source de visualisation de données qui fonctionne bien avec Prometheus et d’autres sources de données. L’outil offre des tableaux de bord personnalisables et interactifs pour visualiser les métriques et les journaux. L’outil est souvent utilisé pour surveiller des mesures de performance comme : le débit, le temps de réponse, etc.
Néanmoins, Grafana a du mal à gérer des charges de travail très importantes. Lorsque le nombre de sources de données et de tableaux de bord augmente, Grafana peut devenir moins performant et avoir des problèmes de latence.
4. Elastic Stack :
L’un des principaux avantages de l’outil est sa flexibilité. Elastic Stack peut être utilisé pour divers cas d’utilisation tels que la recherche de texte intégral, l’analyse de journaux, la surveillance des infrastructures, la sécurité des applications, etc. Peu importe la nature des données que vous souhaitez gérer, Elastic Stack peut s’adapter à vos besoins.
L’un des principaux défis d’Elastic Stack réside dans la complexité de la configuration initiale. La mise en place et la configuration de chaque composant peuvent être laborieuses, en particulier pour les utilisateurs novices. Il faut une certaine expertise technique pour optimiser les performances et assurer une intégration transparente avec les systèmes existants.
Cependant, une fois la configuration initiale terminée, la gestion et l’utilisation d’Elastic Stack deviennent plus faciles.
5. Jaeger :
Jaeger offre une visibilité complète sur les transactions distribuées. L’outil permet de suivre chaque requête à travers les différents services et composants d’un système distribué, en fournissant des informations détaillées sur le temps de traitement, les latences et les éventuelles erreurs. Cette visibilité aide les équipes à comprendre les interactions entre les différents composants et à identifier les problèmes de performance.
Cependant, Jaeger consomme trop de ressources. La collecte et le stockage des traces de transactions peuvent générer une surcharge sur les systèmes, en particulier lorsqu’il s’agit de systèmes à fort trafic ou de charges de travail intensives.
Pour choisir parmi les outils d’observabilité des données , nous vous recommandons de prendre en compte ces facteurs :
- Fonctionnalités et capacités : évaluez les fonctionnalités offertes par chaque outil d’observabilité des données et déterminez celui qui correspond le plus aux besoins de votre entreprise.
- Intégration avec d’autres outils : il doit s’intégrer avec d’autres outils et technologies que vous utilisez déjà afin de faciliter son adoption au sein de votre entreprise
- Facilité d’utilisation et de déploiement : optez pour un outil facile à déployer et à utiliser pour votre équipe
- Coût : comparez les coûts des différents outils et optez pour celui qui a un bon rapport qualité-prix. Aussi, assurez-vous qu’il corresponde à votre budget.
- Evolutivité : l’outil doit être évolutif afin qu’il s’adapte aux besoins futurs de votre entreprise.
Télécharger le livre blanc sur la data observability
IV. Quels sont les piliers de la data observability?
Les cinq piliers de la data observability sont :
- La fraîcheur ;
- La distribution ;
- Le volume ;
- Le schéma ou programme ;
- Le data lineage.
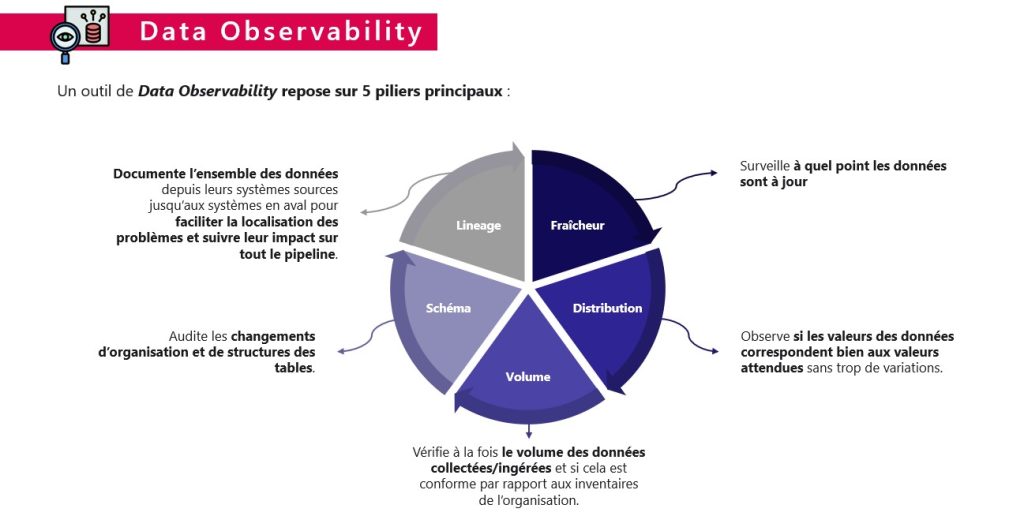
1. Fraîcheur :
La fraîcheur des données fait référence à leur actualité et à leur pertinence temporelle. Elle permet de savoir dans quelle mesure et à quelle mesure les données sont mises à jour.
Les données obsolètes peuvent conduire à des décisions erronées ou à des analyses incorrectes. Il est fondamental de s’assurer que les données utilisées sont à jour et reflètent la réalité la plus récente. Des mécanismes tels que la surveillance en temps réel, la mise à jour automatique et la synchronisation des données sont nécessaires pour garantir la fraîcheur des données.
2. Distribution
La distribution des données fait référence à leur accessibilité et à leur disponibilité. Dans un environnement où différentes systèmes et plateformes peuvent stocker les données, il est nécessaire de pouvoir accéder rapidement et efficacement aux données pertinentes. La mise en place de mécanismes de distribution des données, tels que la réplication, la synchronisation et la mise en cache permet de garantir leur disponibilité lorsque cela est nécessaire.
3. Volume des données
Le volume des données est un défi majeur dans le domaine de la data observability. Avec la prolifération des données provenant de sources multiples, il est essentiel de pouvoir gérer et analyser des ensembles de données massifs.
Les outils et les technologies de big data sont indispensables pour gérer le volume croissant des données et extraire des informations précieuses. La capacité à traiter des volumes massifs de données est essentielle pour garantir une data observability efficace.
4. Schéma ou programme des données
Le schéma ou programme des données fait référence à la structure et à la logique sous-jacentes des données. Comprendre comment les données sont organisées et interconnectées facilite leur analyse et les interprétation. Un schéma ou programme bien défini facilite la recherche, la compréhension et la manipulation des données, contribuant ainsi à une meilleure data observability.
5. Data Lineage
Le lignage des données (data lineage) est le processus qui permet de retracer l’origine et la trajectoire d’une donnée depuis sa création jusqu’à son utilisation finale. En effet, il faut comprendre comment les données ont subi des transformations, où on les a stockées et comment on les a utilisées au fil du temps. Le lignage des données est important pour garantir la qualité, la fiabilité et la conformité des données.
Il permet également de détecter les erreurs et les incohérences potentielles. Ainsi, il facilite la prise de décisions éclairées basées sur des données fiables.
V. Quel est le lien entre la data observability et la modélisation des données?
Il existe un lien étroit entre la data observability et la modélisation des données.
La modélisation des données est un aspect inclus dans la data architecture. Le modèle de données se réfère à la façon dont les données sont structurées, organisées et représentées dans un système ou une application. Elle définit les schémas, les relations et les règles qui décrivent les données et leur logique sous-jacente.
En outre, la modélisation des données joue un rôle important dans l’observabilité des données. Car, elle détermine la structure et le format des données collectées et observées.
Un modèle des données bien conçu facilite la collecte et l’analyse des données pertinentes pour surveiller les performances du système. Il détecte les anomalies et résout les problèmes.
Les données mal modélisées avec des schémas incohérents peuvent compliquer la tâche de collecte et d’analyse des données pour la data observability. Elles peuvent entraîner des lacunes dans la surveillance des performances.
À l’inverse, une modélisation des données appropriée permet de capturer les informations clés nécessaires à la data observability, de définir des métriques pertinentes et de faciliter l’analyse des données pour obtenir des informations précises sur le fonctionnement du système.
VI. Quelle est la différence entre data observability et data quality management?
La principale différence entre le data quality management et la data observability réside dans leur objectif principal. La data observability se concentre sur la surveillance et la compréhension en temps réel de la santé et des performances des données. Cependant, le data quality management englobe l’ensemble du cycle de vie des données, de la collecte à la gouvernance.
La Data Observability et le Data Quality Management sont complémentaires. Car, ils assurent la fiabilité et la pertinence des données dans les organisations.
VII. Observabilité appliquée (applied observability) : tendance en 2023
Selon Gartner, l’observabilité appliquée est une tendance majeure en 2023 en raison de l’évolution rapide des environnements informatiques. Les entreprises adoptent de plus en plus les technologies telles que le cloud computing, les architectures microservices et les conteneurs. Cela rend la gestion des systèmes complexe.
L’observabilité appliquée permet de surmonter ces défis en fournissant une vue d’ensemble des systèmes. Aussi, permet d’identifier rapidement les problèmes potentiels.
Cas d’usage d’observabilité appliquée (Tesla)
Tesla utilise des éléments ciblés de l’observabilité appliquée. La société propose une assurance automobile dans plusieurs États américains aux propriétaires de Tesla. Elle est basée uniquement sur leur comportement de conduite observable en temps réel. Les véhicules Tesla « observent » et mesurent le comportement de conduite à l’aide de capteurs et d’un logiciel Autopilot. Ces véhicules produisent par la suite un score mensuel de sécurité.
Tesla affirme que les conducteurs de niveau intermédiaire pourraient économiser de 20% à 40% sur leur prime. De même, ceux ayant les scores les plus sûrs pourraient économiser de 40% à 60%.
